Containers 101: Docker and Linux Virtualization
Aug 19, 2019
In this blog post, I’d like to talk about software containers and their internals. During the research phase of my graduate project, I investigated the features of the Linux kernel that make possible the creation of containers, such as Docker. I learned a little bit about them, and I will focus mostly on such kernel features.
Probably the most popular of these technologies are Docker containers, but there are others such as Linux Containers (LXC). Docker comes with an API to easily create, configure, and manage containers. It can run on either Linux or Windows hosts. To learn more about Docker and containers in general, I highly recommend reading their documentation and trying the tutorial.
Lets now talk about what a software container is.
What is a Container?
In general, containerization is a system-level virtualization technique, which allows us to create multiple isolated environments in a single host. We often distinguish containers from virtual machines (VMs) by the fact that all containers in a single host share the same OS kernel. Whereas all virtual machines in a single host have a separate OS kernel. This difference is what makes containers more “lightweight” than their VM counterparts. This, of course, has some security implications and trade-offs, but that is beyond the scope of this blog post (there are many online resources on container security).
Virtual Machines vs Containers:
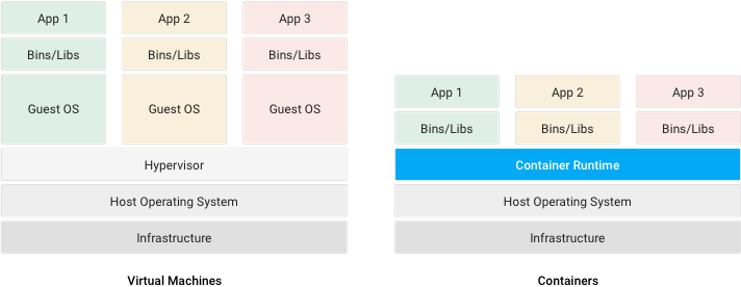
Source: cloud.google.com
{kind=link}
Containers are quite flexible, in the sense that we include only the needed dependencies to run an application. Because of this, deploying inside multiple hosts is easy. For example, in a distributed system, multiple containers (running the same application) spawn in a single host. Depending on the load, our containers easily scale up or down.
The Linux Kernel and Containers
The two main kernel features that give us containers are namespaces and control groups or cgroups. The namespaces provide isolation, and cgroups determine the resources allocated for each container. Additionally, several flag parameters (CLONE_IO, CLONE_NEWIPC, CLONE_NEWNET, CLONE_NEWPID, CLONE_NEWUSER, and CLONE_NEWUTS.) were added to the clone() system call, in support of containers.
In the Linux kernel, the Process Descriptor contains all information related to a process. The process descriptor is a structure (of type task_struct) whose fields contain all process attributes, such as state, file descriptors, thread info, etc. It contains several pointers to other data structures, that in turn, contain pointers to other structures.
One such structure is the nsproxy, and it contains five inner namespaces: uts_ns, ipc_ns, mnt_ns, pid_ns and net_ns. Container (process) isolation is achieved by creating new namespaces for each. The description of these namespaces is as follows:
-
PID namespace (
pid_ns): creates a new PID tree for each container (starting from PID 1) -
Mount namespace (
mnt_ns): provides file system isolation. It allows the container to have its isolated mount points. -
Network namespace (
net_ns): it provides each container with a new set of networking interfaces. -
IPC namespace (
ipc_ns): the IPC namespace gives inter-process communication resources to each container -
UTS namespace (
uts_ns): provides the container with an isolated domain and hostname.
Finally, cgroups limit the use of resources for each container. Quotas are set for memory, CPU, IO, and networking resources. This is an important aspect since all containers share the same host’s resources. cgroups are part of the Linux kernel, and each container is assigned a cgroup configuration file with limits set.
Conclusion
There are a lot of moving parts under the hood when working with containers. Hopefully, this blog post provided a general idea of what these are, and also a better understanding of how applications like Docker and Linux Containers work.