Google’s Cloud Firestore Database: Leveraging The Binary Search Algorithm
Jan 26, 2020
Last week at work I was investigating Google’s Firebase products, in particular, the Cloud Firestore database. So, I decided to take a deep dive into the documentation pages. I learned a lot about integrating the database to an application, its data model, best practices to structure our data, and how to create queries using the available SDKs. As I was reading the description of how the data is organized internally to optimize queries, I couldn’t stop thinking about the basic concept behind this awesome technology by Google.
I think Google’s Cloud Firestore is a great example of leveraging a basic concept in computer science to create a powerful software product. Usually, the most elegant solutions to any problem are those that are clean and simple. This became the inspiration for this blog post.
(Note: I am not sponsored or paid in any way by Google 🙂).
What Is Cloud Firestore?
Cloud Firestore is a NoSQL, highly scalable document database. It is part of Google’s Firestore framework for mobile and web application development. And, it allows us to retrieve and share data among our applications in near real-time. Due to several enhancements over the original Firebase Realtime database, it is recommended for new applications.
How is Data Stored in Cloud Firestore?
First, let’s talk about the way Cloud Firestore stores and organizes our data internally. The data is stored as documents and organized into collections, we can create a hierarchy of collections and subcollections containing documents. Being a NoSQL database, each document is a JSON object (or JSON-like since they support other data types for values). A collection contains a group of logically related documents. Each document, in turn, can point to a collection, creating a tree structure of collections and subcollections, which contain our documents. The diagram below shows an example of such a structure.
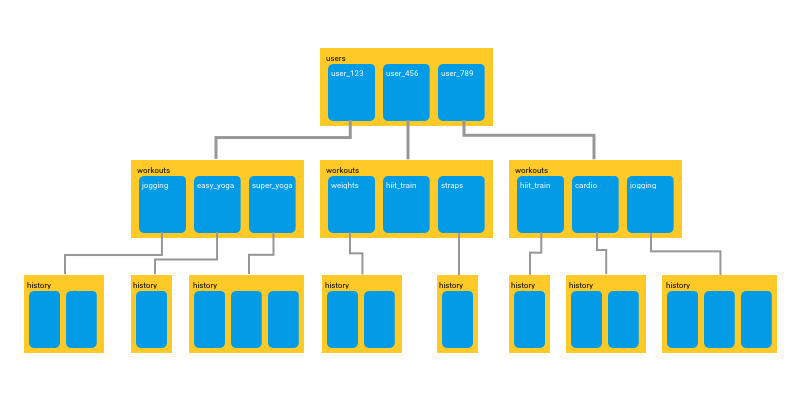
Structure of collections and sub-collections of documents. (source: firebase.googleblog.com)
As a requirement, the root of the tree will always be a collection, even if it contains only a single document. The general pattern to access a document, therefore, would be collection/document/collection/document and so on. Each document contains our data represented as key-value pairs, referred to as fields and values. The size of the documents is limited to 1MB and the number of fields inside the document to approximately 20K fields.
Why is Cloud Firestore So Fast?
By default, Cloud Firestore keeps two lists of sorted indices for each field contained within each document in the database. One list is kept in ascending order and the other one in descending order, based on the value of each field. Recall that in a database system, an index points to the location of a record. These lists are automatically created by Cloud Firestore.
This arrangement of the data has several implications. First, we can see that writes to the database will be slower than reads. But, as we know, NoSQL databases in general favor reads over writes. (A good factor to consider when deciding whether or not to use a NoSQL database, is if in our application reads happen far more often than writes.) Second, and more importantly, when a read is performed, it allows Cloud Firestore to lookup the record’s index using binary search. This is what makes Cloud Firestore queries extremely efficient when retrieving a record or a set of records.
The Power of the Binary Search Algorithm
In Cloud Firestore, query performance is proportional to the size of your result set, not your data set. This is part of what makes Cloud Firestore highly scalable. And, the reason behind this claim is the binary search algorithm. Let’s now recall how binary search works in general. The prerequisite for the algorithm is that the list or collection in which we are searching in is sorted. Recall that Cloud Firestore keeps lists of indices sorted by the value of each field inside the documents, therefore this prerequisite is met.
The inputs to our binary search algorithm are the target value (i.e. the record we want to retrieve from the database) and the sorted collection in which that value is contained (we also pass the starting and ending indices of the collection itself). Now, let’s assume our collection is sorted in non-decreasing order. The algorithm begins by looking at the middle element in the collection. If that element matches our target value, we are done so we return the location of the element. Otherwise, we compare the target value to that of the middle element. If our target value is less than the middle element’s value, we discard the right side of the collection and look on the left side, again starting from the (new) middle element on that side (if the target value was greater, we discard the left side and look on the right side instead). We recursively keep searching in this manner for the target value. This effectively halves our search space each time, until we either find a match or the search fails, meaning that the record was not in the collection. A visualization of this is shown in the figure below.
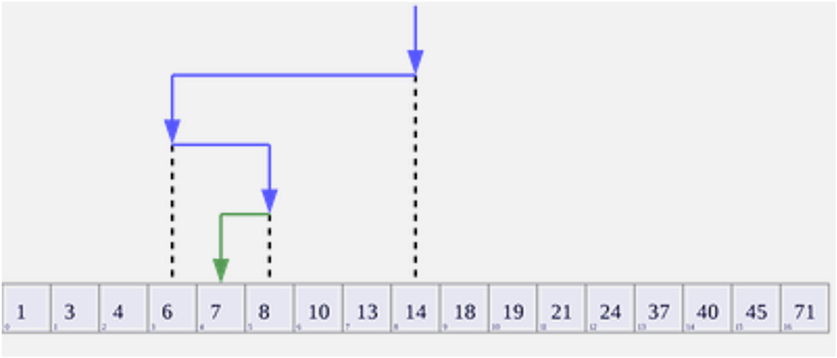
Visualization of the binary search algorithm where 7 is the target value. By AlwaysAngry — Own work, CC BY-SA 4.0
Because the search space is halved after each iteration, the runtime complexity of the binary search algorithm in a collection of $N$ elements is $O(log N)$. This means that finding a record in a collection of, say, 1 million records takes only 20 lookup operations. If the collection doubles its size to 2 million records, we only need 1 additional lookup to find our record. In other words, we say that our runtime complexity increases logarithmically, which is a very good property to have in an algorithm. This is the power of the binary search algorithm. The chart below shows a comparison of common algorithm complexities.
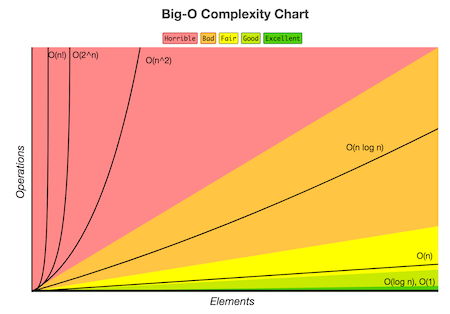
Common algorithm complexities: as the input size increases (number of elements), the number of operations (running time) also increases. A rate of growth of O(log n) is still “good.” source
{kind=link}
Final Thoughts
Google’s Cloud Firestore database can retrieve data in essentially real-time. Along with other enhancements, this is made possible by keeping lists of indices sorted by the values of each field contained inside the data documents. This, in turn, makes it possible to have very efficient queries by leveraging binary search. As always, there are also some drawbacks to this approach. For example, we can’t perform queries involving a not equals ($!=$) clause. In this case, we have to split the query into a less than ($\lt$) query and a greater than ($\gt$) query.
There are always trade-offs to make when deciding what the best solution for our application needs is. I think it’s important to understand and evaluate our options before making a decision. In this case, we get blazing-fast reads, at the cost of relatively slower writes and, possibly, some additional complexity when defining our queries.