Implementing Semantic Search with OpenAI's Embeddings API
Sep, 2023
For the past few months, artificial intelligence seems to have (finally) entered the main stage on the internet. Probably, you've tried ChatGPT, the AI chatbot created by OpenAI. Maybe you had it write your homework, or create a work report for you (no judging, just don't forget to include the actual results in your tables...).
We have AI chatbots, AI-generated text, images, videos, music, code, etc. It seems AI is now everywhere. Some even fear the singularity is near.
In this post, I'll talk about an interesting use case for these AI large language models (LLMs): semantic search. In other words, searching for information based on the meaning of the search terms–rather than simple keyword matching. I'll show you how I implemented semantic search for this blog using the embeddings API from OpenAI.
But before I dive into the subject, I'd like to give you a quick overview of what LLMs are and how do they work.
What Is a Large Language Model?
A language model is an AI model that's trained to predict the next word–or sequence of words–based on an input sequence. It does this by simply choosing the most likely word–or sequence of words–that follow in the sequence. Any model that does this is called a language model. The difference between GPT (Generative Pre-trained Transformer) and others in their category (PaLM, LLaMA, etc.), is that they're trained on massive amounts of data–hence the name large language model.
Furthermore, LLMs are part of a broader category, called generative artificial intelligence. Generative AI can create images, text, music, etc. The latest version of ChatGPT–called GPT-4–is in fact a large multimodal model. Meaning that it can work, not only with text as inputs but also with images, to generate its output.
LLMs can also be used to generate embeddings. These are the main tool I used to implement semantic search. Though embeddings are also useful for other tasks in AI, especially in the area of natural language processing (NLP). Let's now take a look at what embeddings are and how will they help us with semantic search.
Embeddings (a.k.a. Vectors)
An embedding, or vector, is a numerical representation of text–which can be anywhere from a single word, a sentence, or an entire document. The text is mapped to a high-dimensional vector (you can think of it as a list of numbers), and it provides information about the text. For example, the vector representations of the words house and apartment will lie close together in the vector space. This is because house and apartment are semantically similar. The vector is designed to provide semantic information about the text it represents.
The image below illustrates how we can think about different words mapped to their corresponding vectors. As you can see, similar words appear closer together in the vector space.
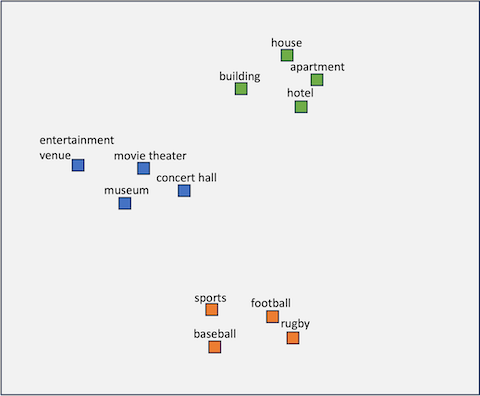
Vector space showing how similar words are grouped closer together.
At this point, you might be thinking about how embeddings can help find information based on semantic meaning. Semantic search is in fact one of the main use cases of embeddings. In the next sections, I'll dive into how I implemented semantic search to find information within all the articles in this blog. I used OpenAI's embeddings API.
Implementing Semantic Search
Let's start by reviewing the general steps for implementing semantic search. After that, I'll go into more details for each. You can find all the code for this solution (written in Python) in my GitHub repository.
To begin, we need to perform the following one-time steps1:
- Pre-process all our text data
- Generate embeddings for the data
- Create a search index with the embeddings and text
- Save the search index to permanent storage
Once we have our search index ready, we can start searching for information. The general steps are as follows:
- Enter the search query text
- Generate an embedding for the query text
- Search for information in the search index (based on vector similarity)
- Arrange and return the results
Text data pre-processing
The goal of pre-processing our data is to create a standardized data format that will work for generating the embeddings and later the search index. Although this is a generic step, its implementation largely depends on the data we have. For example, if you want to search through your archive containing different file formats–e.g. plain text, PDFs, Word files, etc.–your strategy will be different than if you had only one file format2. Luckily, for this blog, I create all my files as markdown–a simple text file format. There were still a few caveats when processing the documents, but this was due to the way I structured my files.
Another important aspect is to decide how to partition our data. As I mentioned in the previous section, an embedding can represent a single sentence, a paragraph, or a complete document. For my purposes, I partitioned each document into paragraphs. A chunk of text the size of a paragraph gives our vectors more context about the subject of each document. I could've created embeddings for whole files, but the search results might not have been that useful. If I only get the text for the whole document, then it's not that different from a keyword search–where the results are the document(s) with the highest number of matching search keywords.
Now let's take a look at some code in the solution, specifically the process_markdown.py file. The following function is executed for each markdown file to extract the paragraphs3. Notice that the markdown file is first converted to HTML. This makes it simple to extract each paragraph in the document and add additional information for each one. Also, notice I had to do some cleanup of invalid paragraphs. For each paragraph, I create a dictionary containing additional metadata, such as the document's title, a paragraph ID, and an empty field for its corresponding embedding. This field will be filled in later on when we generate our embeddings.
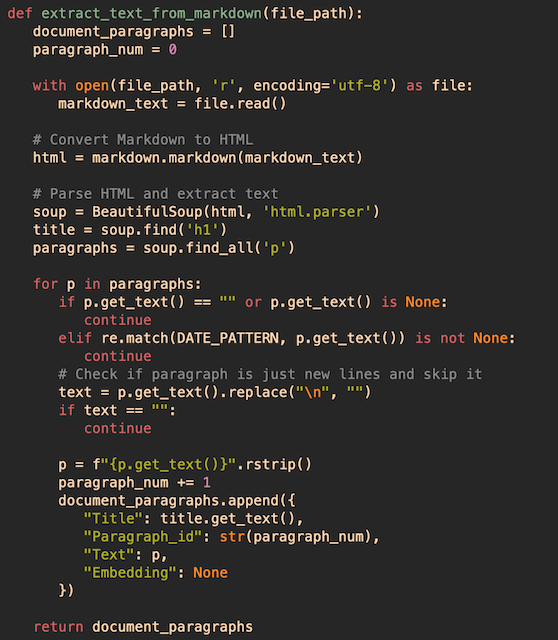
After processing all files in my document folder, the script returns a JSON-like list of dictionaries. Each dictionary corresponds to a paragraph with additional metadata. The returned data structure looks like this:
[
{
"Title": "<document title>",
"Paragraph_id": "<paragraph number inside the document>",
"Text": "<paragraph's text content>",
"Embedding": "<text's embedding (initially empty)>"
},
{
...
},
]
This provides good flexibility for the upcoming tasks of getting embeddings and creating the search index.
Generating embeddings with OpenAI's API
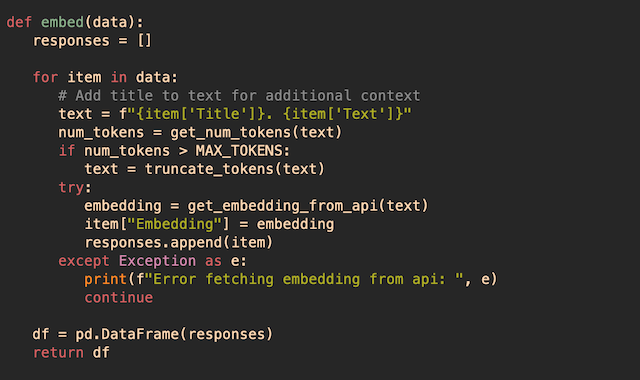
Once we have all the data in the appropriate format, we're ready to generate the embeddings. For each dictionary in the list, I take the "Text" and combine it with the "Title" value (this serves to add context to the paragraph's text). Using the resulting text as input, I make a call to OpenAI's embeddings API4. The response from the API contains a 1536-dimension vector representing the paragraph's text5. Now, looking at the semantic_search.py file, the function below makes the API call and returns the embedding from the response.
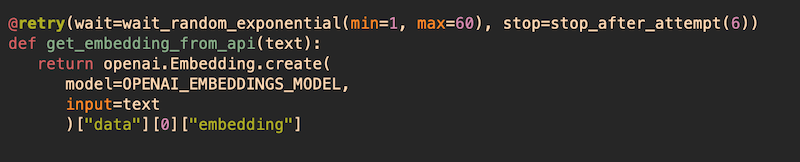
I then use the returned vector to update the "Embedding" field in the corresponding dictionary. Once this is done for every paragraph, we have all we need to create the search index.
Creating a search index
When it comes to creating a search index, there are quite a few options to choose from. For example, we have approximate nearest-neighbor vector search libraries. Some of these include Annoy, FAISS, and ScaNN. They are easy to set up, but usually only store vectors. We could also use a vector database. This kind of database is optimized to work with vectors. They include more advanced features than libraries and allow us to store vectors and text. Some vector databases include Weaviate, Qdrant, and Pinecone. It's even possible to use PostgreSQL as a vector database.
Ultimately, the choice of technology for a search index depends on the needs of your application.
For my solution, I went with yet another option. I used the pandas Python library to create a DataFrame file from my list of dictionaries. Then the DataFrame file is saved to disk as a CSV file. Using pandas allowed me to easily manipulate my data. It was also easy to create the CSV file, write it to disk, and later load it again when searching for information. The function shown below returns the DataFrame–which is later saved as a CSV file.
Up to this point, we have prepared our data and created a search index. We can now start querying for information using semantic search.
Querying the search index
The first step in querying for information is, of course, entering the query text (the solution includes a CLI tool that allows me to enter the queries). Then we need to get an embedding (or vector) that represents the search text. Finally, we just need to find the vectors, in our search index, most similar to the query vector.
We say that a vector is similar to another when the distance between them is short. A common way to find the distance between two vectors is by calculating their cosine similarity. In this case, the cosine similarity is a value between -1 and 1. Values closer to 1 indicate higher similarity, while values close to -1 indicate less similarity. I used NumPy arrays to easily obtain the cosine similarity between two vectors. This is shown in the code below.

I get the similarities between the query vector and every vector stored in the search index. Then I sort the results in descending order. Something worth mentioning is that I have only a small amount of data. Recall that I only used the articles in this blog. Because of this, it's fast to search through my entire search index. For large datasets, it's better to use a vector database, or an ANN library–which are optimized for this use case (see the previous section).
Showing the Results
The CLI tool (cli.py file in the solution) also lets me specify the number of records to return per query. These will be the ones with higher similarity to the query vector. To query the search index, I run the following command in the terminal:
$ python3 semantic_search.py --query <query text> -n <number of results>
Here, I use the option --query to enter the search text. The -n option indicates the number of results to return–where the argument is an integer number.
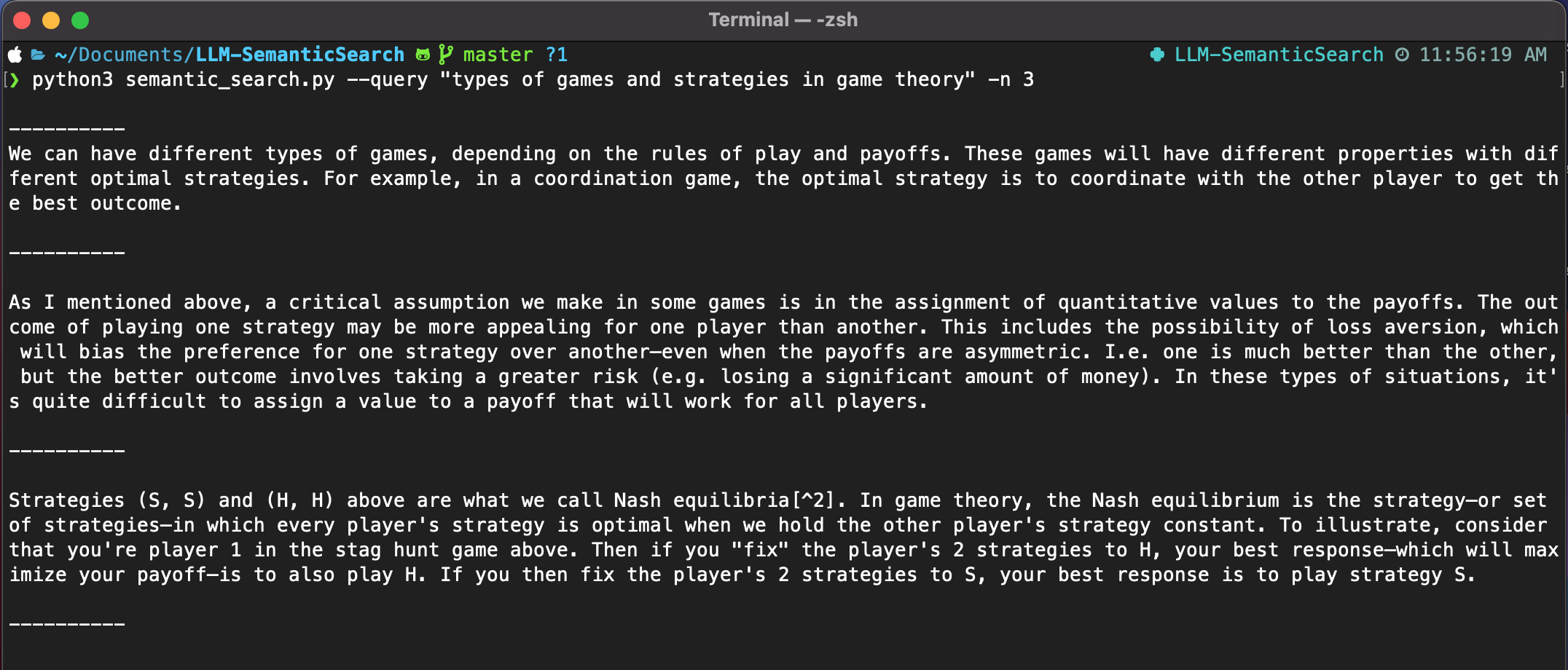
As shown in the screenshot below, I asked about game theory–a blog post I wrote some time ago–and to return the three most relevant results.
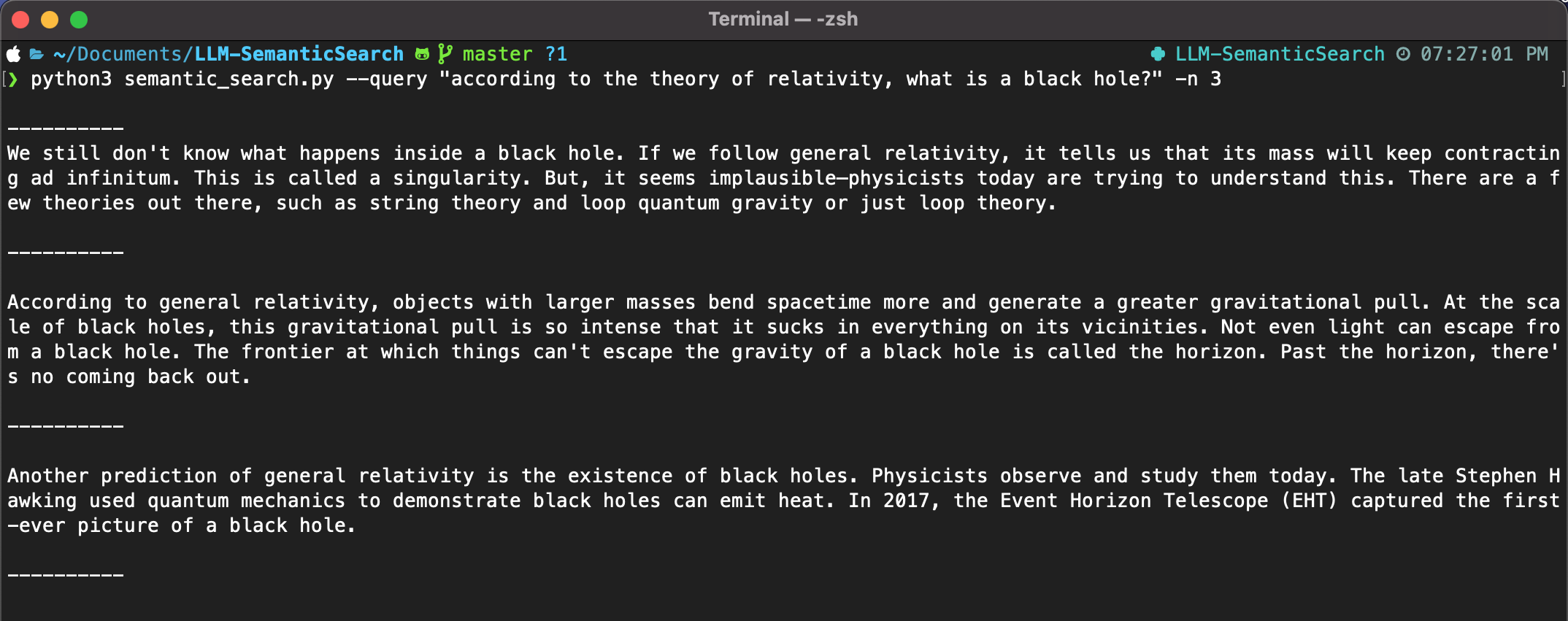
In the query below, I asked about black holes and the theory of relativity. Notice how the system understands the meaning of my question and returns the best three results.
And this is it. We've implemented semantic search using OpenAI's embeddings API. I generated vectors and indexed the information in this blog. With this in place, I can make queries and get results based on the semantic meaning of the query.
Conclusions
Hopefully, going through the process of implementing semantic search gave you a good idea of the capabilities of LLMs. It's now possible to create a robust search system with only a few Python scripts. The best part is that it can be customized to work with your own data. Think about all the possibilities and other amazing use cases.
As of this writing, there are a few improvements I can make to the solution. For instance, I need to better clean up my data during the pre-processing stage. As you can see in the query below, some of the results don't contain useful information.

Also, you may have noticed other details in my solution code. For example, I use a cache to store the vectors of previous queries. This helps to avoid making a call to the embeddings API for repeated search terms6. Other features can be added to the solution, such as a function to update the search index when new data is added–without re-generating the embeddings for text that hasn't changed. We can also use the search results, pass them through a generative system–e.g. OpenAI's completions API endpoint–and return the answers in a more chatbot-like experience.
It's impressive what these AI models can do. But, we still need some tweaking to do to get the best results. So it seems to me we still have a few ways to go before reaching the singularity.
Notes:
-
These steps will need to be repeated if we need to update or add more data to our search index. ↩
-
Some models support generating vectors for other types of files such as images, audio, and video. ↩
-
Keep in mind that this part of the solution is tailored to my files. It might not work in general without making some changes. ↩
-
If you take a closer look at the code in my repository, you'll see I needed to do some additional pre-processing before calling the API. E.g. I needed to verify the number of tokens for each paragraph and truncate them if needed. ↩
-
Check out this blog post for more details about OpenAI's /embeddings API endpoint. ↩
-
I didn't touch on the costs of using the API, but it's an important consideration if you have a large application. The cost breakdown is posted on OpenAI's website. ↩